簡稱 DNN 是 深度學習一種人工神經網路模型
由 多層感知器(Multilayer Perceptron)組成
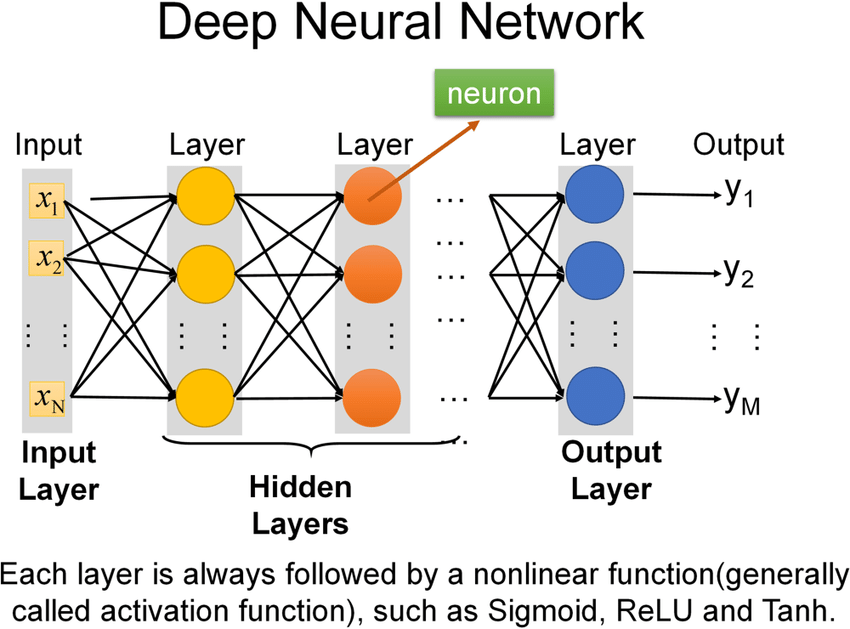
多層感知器是一種人工神經網路,輸入層、隱藏層、 輸出層 組成
輸入層 |
接收資料 |
|---|---|
輸出層 |
輸出結果 |
隱藏層 |
從資料中學習模式 |
影像辨識 |
識別圖像中的物件 |
|---|---|
自然語言處理 |
理解自然語言、機器翻譯、語音辨識、文字分析 |
語音辨識 |
將語音轉換為文字 |
機器翻譯 |
將一種語言翻譯成另一種語言 |
推薦系統 |
向用戶推薦喜歡商品或服務 |
優點 |
資料學習複雜模式,解決傳統機器學習模型無法解決問題 |
|---|---|
缺點 |
需要大量資料進行訓練,訓練過程可能很耗時,可能存在過擬合(Overfitting)問題 |
利用 反向傳播演算法 訓練DNN,是一種梯度下降法,計算損失函數DNN權重梯度,使用梯度來更新權重,減少損失函數值
前向傳播:將輸入資料饋送到DNN中,計算每個神經元的輸出值計算損失:計算損失函數值反向傳播:從輸出層開始,逐層反向傳播,計算每個神經元的輸出值相對於其輸入值梯度更新權重:使用梯度更新DNN權重a_l = σ(w_l * a_{l-1} + b_l)
L = loss(a_L, y)
δ_L = ∂L/∂a_L
δ_l = ∂L/∂a_l = w_{l+1}^T * δ_{l+1} * σ'(z_l)
w_l = w_l - α * δ_l * a_{l-1}^T
b_l = b_l - α * δ_l
a_l |
第l層神經元輸出值 |
|---|---|
σ |
激活函數 |
w_l |
第l層神經元權重 |
b_l |
第l層神經元偏置 |
L |
損失函數 |
y |
目標值 |
δ_l |
第l層神經元誤差 |
α |
學習率 |
import numpy as np
# 輸入資料
x = np.array([[1, 2], [3, 4]])
# 目標值
y = np.array([[0, 1], [1, 0]])
# DNN
class DNN:
def __init__(self, n_features, n_hidden, n_outputs):
self.w1 = np.random.randn(n_features, n_hidden)
self.b1 = np.zeros(n_hidden)
self.w2 = np.random.randn(n_hidden, n_outputs)
self.b2 = np.zeros(n_outputs)
def forward(self, x):
a1 = np.dot(x, self.w1) + self.b1
z1 = np.tanh(a1)
a2 = np.dot(z1, self.w2) + self.b2
z2 = np.sigmoid(a2)
return z2
def loss(self, y_pred, y_true):
return -np.sum(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
def backward(self, y_pred, y_true):
delta2 = y_pred - y_true
delta1 = np.dot(delta2, self.w2.T) * (1 - z1**2)
grad_w2 = np.dot(z1.T, delta2)
grad_b2 = delta2
grad_w1 = np.dot(x.T, delta1)
grad_b1 = delta1
return grad_w1, grad_b1, grad_w2, grad_b2
# 訓練
model = DNN(2, 4, 2)
for epoch in range(1000):
y_pred = model.forward(x)
loss = model.loss(y_pred, y)
grad_w1, grad_b1, grad_w2, grad_b2 = model.backward(y_pred, y)
model.w1 -= 0.01 * grad_w1
model.b1 -= 0.01 * grad_b1
model.w2 -= 0.01 * grad
資料來源:深度學習
DNN(深度神經網路)的全面認識

